In this blog, we’ll give you a detailed review of data retention strategy, policies, and the challenges relating to them. You’ll also see how you can reap some of the benefits of having these clearly defined in your organization. If you’re responsible for data in any enterprise-sized organization, you’ll need the information in this article to help your organization reduce risk, increase efficiency and productivity, and reduce costs.
What is Data Retention?
 Data retention is the process of storing information for a specified period. It is relevant to all businesses that produce and retain data to service their customers and comply with government or industry regulations.
Data retention is the process of storing information for a specified period. It is relevant to all businesses that produce and retain data to service their customers and comply with government or industry regulations.
Without a data retention strategy, companies might store too much information or keep it longer than needed, which leads to operational inefficiencies, increased costs, and legal and security risks.
To formalize the data retention strategy, every organization needs a data retention policy to codify the requirements and give clear guidance across the organization: what data needs to be kept and how it should be archived.
Let us first look at the strategy's implications, which are meant to be defined on a high level and provide a long-term outlook.
What drives a Data Retention Strategy?
The defining factors for a data retention strategy are the three pillars:
- data creation and usage,
- regulatory oversight, and
- exposure to data privacy and protection
The first factor is, of course, down to the nature of the business. If your business is involved with the building, management, or servicing of a nuclear power plant, it is evident that any decision, change, or failure needs to be kept for the long-term – and that can mean until 25 years after the plant has been decommissioned. The same company might have other projects, regular office buildings, or commercial property where it is sufficient to retain the data for ten years.
The same is true for car insurance, where typically most records are stored for ten years or a similarly well-defined period, while life insurance should retain the information for at least ten years after the death of the insurance owner – which is quite tricky to put into an IT policy.
On the other hand, businesses with a short-term focus, such as a hotel company or a telco provider, will stick to short-term retention policies, as their businesses tend to be transactional and without long-term implications.
In those examples, we can already identify some of the drivers for the second pillar:
Anything that has to do with a nuclear facility is highly regulated, as is the retention of the records for a life insurance company.
It makes sense to mandate a complete track record of anything that adds to the trustworthiness of a reactor and to establish a regime of openness and transparency.
And for consumer protection, it is also obvious that you mandate the retention of all documents at a life insurance company to prevent a “dog ate the contract”-like situation once there is a dispute about the pay-out terms after 40 years of taking the client’s money.
Until a few years ago, the common approach to data retention was therefore very straightforward:
What does the regulator say, and how long does the business need the information beyond that?
But things changed massively with the introduction of data privacy regulation under the umbrella of digital consumer rights. Legal Acts like the European GDPR or the CCPA in California fundamentally questioned the long-held belief that it was the company’s data that was to be retained and stored, but suddenly a large subset of the data was only under the stewardship of the organization and owned by the customers or the employees.
This led to the current problem of conflicting retention requirements and special purpose processes around data subject requests and the colloquially known “right-to-be-forgotten".

The High-Level View: Systems and Channels
The place to start with any data retention strategy is to create a very basic map of the various communication channels the organization uses to communicate with the outside world. Place a particular focus on channels used for storing and transferring records, means, and modalities of customer communication, and, of course, the departments that produce 1st tier records such as contracts, invoices, and intellectual property records such as research and development, including patent applications.
This map should not only include electronic communication but also paper trails and - to a certain extent – voice communication if this is related to a transaction, such as renewing a mobile phone contract.
Here are typical categories of communication channels that should be part of this exercise:
|
Team Collaboration
Jabber, Workplace by Facebook, Cipher …
Enterprise Social
Jive, Yammer, …
Web & Video Conferencing
Teams, Slack, Zoom
Cloud-PBX / VoIP
RingCentral, Cloud9, ...
|
Social Media
Facebook, Twitter, YouTube, …
Mobile / Crypto Messaging
WhatsApp, WeChat, Telegram, …
Financial Platforms
Bloomberg, EIkon Refinitiv, IceChat, …
File & Document Collaboration
Dropbox, Google Drive, SharePoint, ...
|
As you can see, a staggering number of communication options are available. The first step is to determine which are officially adopted, and unofficially used, and which ones can, or should be restricted.
This might sound awkward to some readers, but tolerating the use of WeChat for customer and intra-bank communication in Asia has led to multimillion-dollar fines for several well-known institutions. In this case, it would have been necessary to either block or explicitly prevent the use of those apps or – even better – implement a retention strategy to keep that communication compliant.
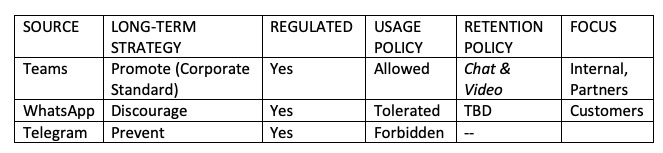
As you can see in the example above, the strategy needs to be mapped to a Data Retention Policy on the operational side. It is best practice to split the policy itself from the strategy.
One could even argue to define the strategy on the category level (Email, Chat, Web-Conferencing) and then break down the actual products and apps in the policy so that the strategy will need less frequent adjustments.
Including Data Privacy in your Data Retention Strategy
You might wonder why we have not touched on the subject of Data Privacy in the table above. In our view, Data privacy will only touch a subset of the systems in question and only in selected geographies or regions.
A laboratory information management system (LIMS) in a pharmaceutical company is unlikely to hold any privacy-related data, nor should the company’s social media property, as that information is obviously public information and can be deleted by the user herself.
On the other hand, many email systems have been historically used for receiving job applications with detailed CVs of the candidates. These are documents that contain very, very detailed personal and protected information, as any GDPR-savvy Data Protection specialist will tell you.
There are now several clarifications that mandate companies to destroy this information after six months for any candidate that has not been selected for the job. Those HR mailboxes should be excluded from the corporate email archiving policy – or even better – be moved to a job application portal separate from the corporate email system.
The Data Privacy Map required by GDPR will look quite like the map we have created for the Data Retention strategy. Data mapping is an essential component of the GDPR. It is the foundation for fulfilling all other legal requirements under the GDPR, such as responding to data subjects’ requests, conducting data protection impact assessments, or maintaining records of data processing activities.
On one hand, it is essential to understand where electronic information containing personal data is stored and how long it is retained. On the other hand, Article 30 of the GDPR requires controllers and processors to maintain a record of data processing activities (ROPA). These need to include process activity information, such as the purpose of processing, legal basis, consent status, cross-border transfers, DPIA status, and more.
This extended Data mapping helps organizations comply with GDPR by collecting and maintaining a list of data processing activities across the business.
So, does it make sense to try and encompass both kinds of documents in a single strategy?
Typically, it is not feasible, as it serves different audiences and different requirements.
At the same time, it is obvious that specific, often contradictory retention requirements of GDPR must be fed back into the general Data Retention strategy and any conflicts need to be resolved.
Why You Need a Data Retention Policy
A data retention policy clarifies what data should be stored or archived, where that should happen, and for how long.
It defines how the organization will store and manage data for compliance or regulatory reasons and the disposition once the data is no longer required.
Even a simple data retention policy should clarify how records and data should be formatted, how long they must be kept, and what storage system or devices are used to retain them.
Once a data set exceeds its retention time, the policy should specify whether the data can be deleted or moved to secondary (cold) storage, depending on business requirements.
These decisions will typically be based on local laws and regulations (GDPR) or the rules of the industry’s regulatory body.
Why Not Keep Everything Forever?
While it is important to retain historical data for business use, most data retention policies exist to fulfillregulatory requirements.
Data retention policies for electronic communications are often the crux of data management. While one could argue that there is already a long tradition of filing paper documentation, information created as large streams of electronic communications cannot as easily be stored or cataloged in traditional filing systems and does not contain business records.
Nearly 50% of all business communications is “noise”: anything from airline newsletters, legitimate advertising, IT notifications, or daily updates from social networks such as LinkedIn.
But telling which half of the information is irrelevant has historically been difficult.
In the past, many records management experts, therefore, translated the legal or tax-focused retention requirements into blanket statements, such as
“Keep all emails in a ten-year retention category”
Even worse, this was often done without explicitly requiring the corresponding expiry mechanisms to automatically prune those emails once they are past their due date.
Today, they struggle to enforce this deletion process for various reasons:
- Ongoing cases / legal holds
- Data across different departments and geographies with conflicting retention requirements
- Potential long-term records such as contracts (life insurance) or IP records (patents)
- And above all: Finding a senior executive signing off the permanent deletion of data
On the other hand, most organizations do not have the financial ability to retain all data forever, nor is that even a desirable goal given the emergence of harsher data privacy requirements (such as GDPR) which might require a much shorter retention period.
For instance, personnel records and sensitive financial or medical records may all have different (shorter) retention periods.
Covering The Basics with an Industry-Specific Template
Due to the complex nature of the regulatory frameworks, organizations often use an industry-specific data retention best practices template that includes several different retention puzzle pieces:
- Publicly traded companies in the US must establish a Sarbanes-Oxley Act (SOX) data retention policy.
- Organizations that accept credit card payments must establish Payment Card Industry Data Security Standard (PCI DSS) data retention policies.
- Healthcare organizations must develop data retention policies that adhere to the Health Insurance and Portability and Accountability Act (HIPAA).
- Businesses that process or store personal information about EU citizens must comply with the General Data Protection Regulation (GDPR), even if they operate from a non-member state.
Using a simple template is just a starting point, which should be refined to your organization’s needs.
Why a Template is Only The Starting Point
Many organizations think that a template that is used by their peers or has been quickly put together by their legal advisors is enough to deal with their Data Retention and management requirements, but that is rarely the case. This is due to several factors that make a Data Retention strategy a very individual endeavor.
The regulatory landscape is constantly evolving
In all parts of the world, regulations are constantly shifting, especially as the influence of laws such as Europe’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) grows. That makes complying with those challenging regulations a moving target.
Data keeps growing, and the number of sources is still diversifying
The biggest problem is not just the growth of data itself but the continuous addition of new tools and sources while keeping an ever-growing “zoo” of legacy systems. Just moving from an on-premises email system with a corresponding email archive can be a costly and challenging exercise, but having important data stored in systems that no longer receive security patches or cannot be searched easily can be even more expensive and is a risk that should not be taken lightly.
Another problem is the growing use of cloud platforms that do not allow customers the required level of access and control over the data they store. This loss of data sovereignty can not only be an inconvenience, but with some vendors charging data extraction fees in the thousands of US dollars per terabyte, it can become very costly to rehome the data into the company’s own cloud environment.
And that is just the systems you know of. Unfortunately, there is still some “laissez-faire” in some departments when it comes to understanding the Data Retention requirements and the duty to document which external systems are used.
Quickly feeding a cloud-based AI system with testing data from a production backup might cause several problems regarding data privacy, retention, and data security without anyone in IT Management or the GRC department even knowing about the system and the data involved.
Ultimately, you are responsible for everything your employees create and every platform they use.
Implementing a Data Retention Strategy – Best Practices
These five steps will aid in this process and help you operationalize a data retention strategy across your organization.
1. Constantly monitor and adjust the data regulatory requirements
Implementing a process to gather regulatory intelligence is crucial for creating a reliable collection of retention and data privacy requirements.
While it should be centrally coordinated, it needs to cover all geographic locations and business units in which your organization operates.
Understand the various record classes you need to keep for regulatory, legal, and business purposes
For naming the different record classes and a consistent system of filing, the creation and implementation of a company-wide taxonomy will help to establish a trustworthy records management process.
2. Create a “Data Map” regarding the business and geographic data regulations
There will likely be different data retention, and privacy requirements within the different business or geographic locations your organization operates in. The best way to update and visualize these conflicting policies is by creating a true map of regions or countries that have special requirements.
While Europe has finally managed to consolidate over 20 different data protection laws into one – GDPR – there are still some national specialties, such as banking laws in Luxemburg or the fact that Switzerland has fundamentally adopted GDPR but has also created some more restricted requirements for banking customers.
And who knows what the future holds for EU citizens' data stored in the UK in the not-so-unlikely event of diverging future regulations?
It is therefore vital to determine which regulations may differ between locations and how the company can identify the presence and sources of records and personal data to which your retention obligations apply across business units and geographies.
3. Maintain the data’s regulatory and organizational information
Today data is often traveling through various internal and external systems.
While your data might have been collected in Germany or France, the Account Manager fulfilling the order might be based in the UK, using a CRM system where the data storage is in the US.
To decide where data retention obligations will be applicable, where the data is and should be stored and what data might need to be moved or excluded from certain processes, it is mandatory to not only understand the source of the data but to make its origin identifiable throughout its lifecycle.
Therefore, implementing a data source catalog and a metadata schema that keeps this information intact is crucial to maintaining and sustaining the strategy over time as data retention regulations and obligations change.

4. Identify and manage the various regulatory subjects
There are different stakeholders in any organization from a regulatory standpoint:
Employees, executives, service users, consumers, patients, partners, business advisors, and legal counsel. This all depends on the vertical industry you are in.
It is important to understand which group is regulated under which law and what regulatory body. The CFO of a public company will have retention & surveillance requirements stemming from the Sarbanes-Oxley act (SOX), while the users of a digital service might be protected by GDPR if that service stores Personally Identifiable Information (PII)
Creating a map and an operating model, including training and/or communications for those stakeholders, help with a proactive approach to deploying your Data Retention Strategy
5. Communicate regularly, and communicate openly
The only way to ensure your data retention strategy works is by communicating the relevant retention obligations to the employees. An excellent way to make this work is by regularly meeting with IT management and their counterparts on the Data Protection / Data privacy side. Knowing which projects are about to be kicked off, which systems are introduced and where existing tools are getting replaced means you can get involved in the process at the right time and put data retention requirements into the project plan or vendor selection process.
Another vital step is to educate employees on the processes and technologies used to identify records and personal data in existing data stores, applications, and business tools. The more people understand what needs to be kept, what for, and how long, they can already put appropriate measures and customized policies into the applications they use. A good example is moving to Exchange Online, where administrators can create a comprehensive retention framework for email, which can then be applied to all mailboxes or specifically adjusted for certain departments.
Closing Thoughts
A good Data Retention Strategy should keep track of the data and how the organization uses it. But it can also inform about how the company “should” use the data.
And in that context, it might be feasible to discuss which systems are really required and which ones are only remaining for historical reasons. Is anyone still using the chat feature of the intranet, given that Teams is integrated into many other workflows?
And if nobody uses the intranet chat, why not switch it off and move the chat data to a searchable archive?
At Cloudficient, we help companies who are making those decisions. Whether you have systems at their end of life and need to be replaced for security reasons, or if you have inherited a theme park of apps and servers from a recent acquisition. We help to consolidate and transition the information on these systems to your platforms of choice.
That is what we call “empowering digital transformation”.
With unmatched next generation migration technology, Cloudficient is revolutionizing the way businesses retire legacy systems and transform their organization into the cloud. Our business constantly remains focused on client needs and creating product offerings that match them. We provide affordable services that are scalable, fast, and seamless.
If you would like to learn more about how to bring Cloudficiency to your migration project, visit our website, or contact us.
-3.png?width=250&height=33&name=Untitled%20design%20(18)-3.png "Cloudficident Logo")
-3.png?width=527&height=69&name=Untitled%20design%20(18)-3.png "Untitled design (18)-3")
.png?width=600&height=79&name=Untitled%20design%20(18).png "cloudficient logo")